1. Introduction
In recent years, humanoid robots and quadruped robot dogs have frequently gone viral, becoming hot topics across the robotics community. For these types of robots, motion control is undoubtedly one of the core technologies. Reinforcement learning (RL), as one of the primary approaches to motion control, also fully leverages the model-inference capabilities of the RDK series boards. Therefore, we attempted to deploy an RL model on the RDK S100 and explore its performance on a real robotic platform.
In this experiment, we use Limo Dynamics’ Point-Foot robot, and perform inference on the RDK S100 (the MLP model is small and consumes very few resources). The project is based on the paper “CTS: Concurrent Teacher-Student Reinforcement Learning for Legged Locomotion”, co-authored by Limo Dynamics. We reproduced and modified the corresponding GitHub project rl-deploy-with-python, adding BPU inference support for the RDK S100.
This project provides a complete engineering implementation, suitable as a foundation for reproduction and optimization. Therefore, we chose this solution for deployment and testing. The complete workflow consists of three stages:
Model Training → Model Quantization → On-board Deployment
2. Paper Overview and Training
2.1 Paper Summary
In the paper “CTS: Concurrent Teacher-Student Reinforcement Learning for Legged Locomotion”, the authors and Limo Dynamics introduced an innovative approach aimed at enhancing legged robots’ locomotion performance on complex terrain. Traditional teacher-student RL frameworks adopt a two-stage pipeline: reinforcement learning is first used to train a teacher policy with privileged information (terrain, contact force, etc.), and then supervised learning distills knowledge into a student policy trained only on proprioceptive data.
CTS (Concurrent Teacher-Student) breaks this pattern by introducing a parallel training framework, where the teacher and student policies are trained simultaneously under a unified reinforcement learning structure. This not only simplifies the training process but enables the student policy to learn through reinforcement learning objectives rather than pure imitation, improving policy generalization and robustness.
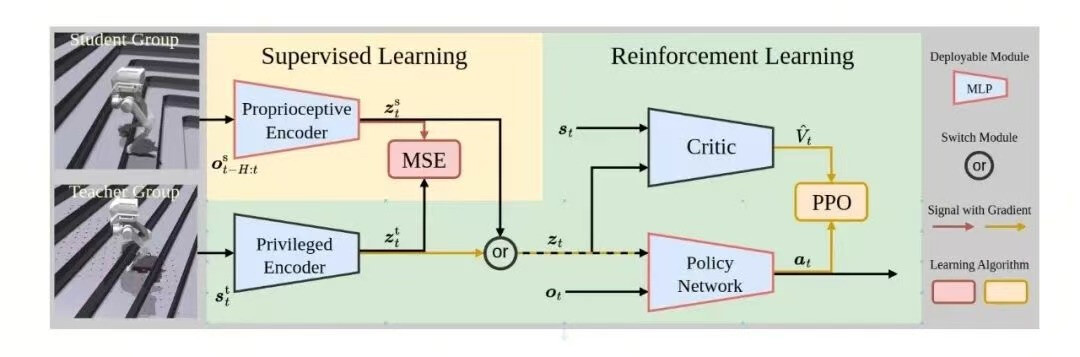
The CTS framework is built on Proximal Policy Optimization (PPO) with an asymmetric actor-critic design. The teacher policy leverages a privileged encoder to process full-state information, while the student policy processes proprioceptive data via a body encoder. The two policies share the same actor and critic networks, ensuring consistency.
During training, the student policy optimizes itself via reinforcement learning while minimizing latent-space differences with the teacher, allowing it to make effective decisions even without privileged information.
CTS was validated across multiple robot platforms, including different quadruped robots and a highly challenging point-foot biped. Results show that CTS reduces velocity-tracking error by up to 20% compared to standard two-stage learning on uneven terrain (slopes, stairs, and irregular obstacles). It also demonstrates excellent robustness to external disturbances and strong sim-to-real transferability.
2.2 Model Training and ONNX Export
For detailed training instructions, refer to the official Limo Dynamics documentation:
-
RL Environment Setup: LimX 文档 | LimX 文档
-
RL Model Training: LimX 文档 | LimX 文档
A brief summary of the workflow:
-
Configure the IsaacGym simulation environment and set the robot type via environment variables.
-
Start simulation training.
- View training results.
- Export the ONNX model.
Inspection of the architecture shows that the model is composed of linear layers with ELU activations.
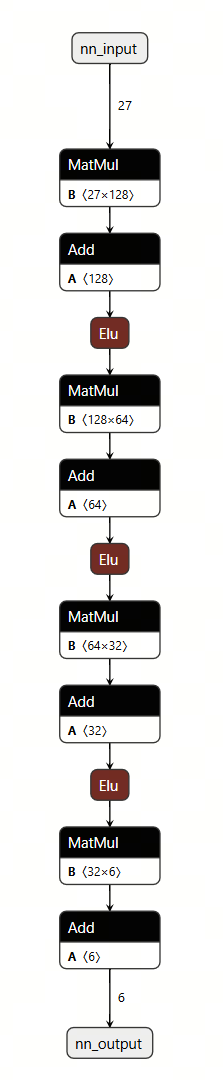
3. Model Quantization
3.1 Environment Setup
# Pull the S100 toolchain Docker image (contact an engineer for image and OE package)
# Extract the quantization project folder (contains config files and calibration data)
# Place the exported ONNX model inside the quantization folder (ensure model name matches config file)
sudo docker run -it --entrypoint="/bin/bash" \
-v <local_folder_path>:/limx_model_convert_s100 \
<docker_image_id>
3.2 Model Quantization
cd /limx_model_convert_s100
# Quantize adaptation_module, result stored in model_output_ad
hb_compile -c ad_config_bpu.yaml --march nash-e
# Quantize body model, result stored in model_output_body
hb_compile -c body_config_bpu.yaml --march nash-e
Quantization results:
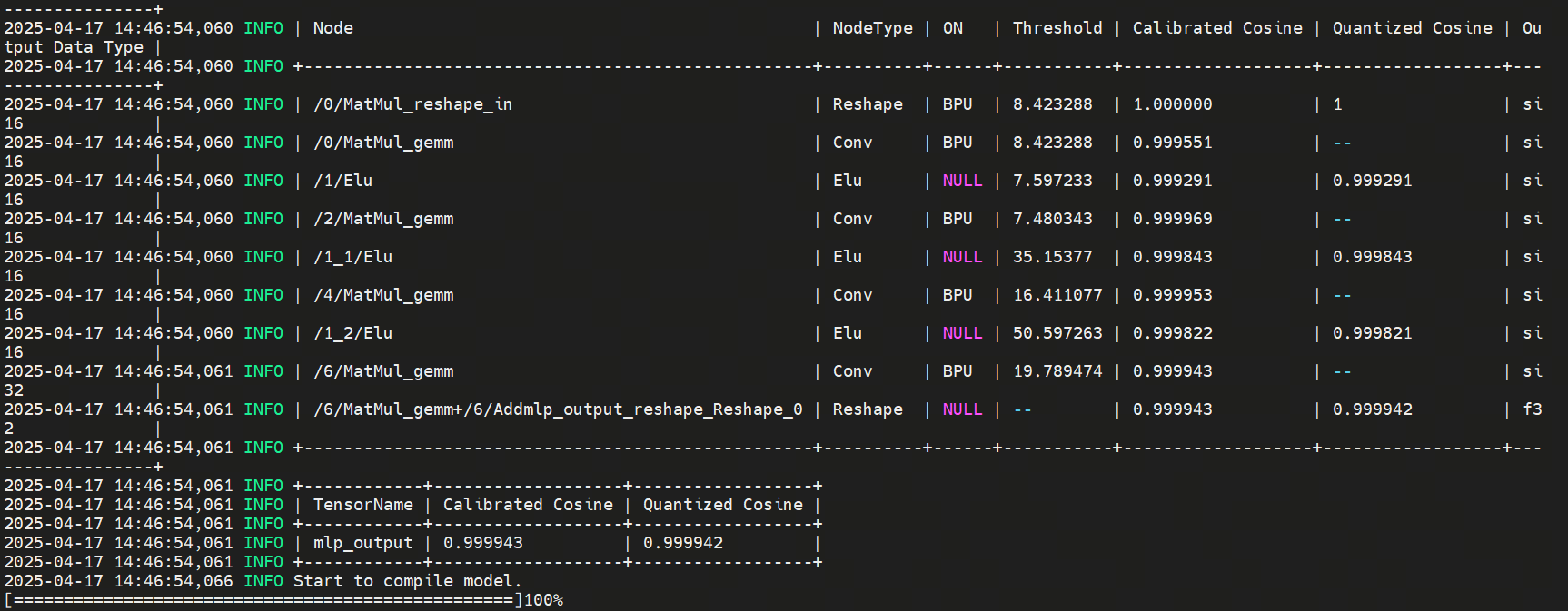
Interpretation:
Refer to the bottom 2 × 3 table. It shows the cosine similarity between the final mlp_output and CPU output. All cosine similarity values exceed 0.9999, confirming extremely high accuracy retention.
4. On-board Deployment
4.1 Bill of Materials
Only a few additional components are required beyond a laptop:
-
Limo Dynamics TRON-1 Point-Foot Robot ×1
-
TRON-1 Remote Controller ×1
-
RDK S100 Board ×1
-
3D-printed mount for placing RDK S100 on the robot head (Nano-tape or duct tape recommended)
-
Ethernet Cable ×1
-
XT60-to-DC Power Cable ×1 (for powering S100 from the robot battery)

Assembly steps:
-
Ensure the robot and remote controller are fully charged.
-
Attach the 3D-printed mount to the TRON-1 head using nano-tape (or duct tape).
-
Secure the RDK S100 onto the mount using screws.
-
Power the S100 using the XT60-to-DC cable.
-
Connect the robot’s Ethernet port to the S100’s Ethernet port.
-
Final assembly example (tape shown in the picture; nano-tape recommended):

4.2 Environment Setup
git clone --recurse https://gitee.com/chenguanzhong/rdk_s100_limx.git
pip install pointfoot-mujoco-sim/pointfoot-sdk-lowlevel/python3/aarch64/limxsdk-*-py3-none-any.whl
Set robot type (recommended to write into bashrc):
echo 'export ROBOT_TYPE=PF_P441C' >> ~/.bashrc && source ~/.bashrc
Compile the model-inference library:
cd ~
git clone https://github.com/wunuo1/model_task.git -b s100
mkdir build
cd build
cmake ..
make -j4
4.3 Run the System
cd rdk_s100_limx
python rl-deploy-with-python/main.py 10.192.1.2