This post is mainly aimed at the problems in the deployment process of the newer version of YOLOv5. Except for the changes listed below, other changes can be handled according to the official methods. In addition, if you use YOLOv5 2.0, please directly follow the official method
For cannot reshape array of size… The problem solving method into shape (1,x,x,3,x) mainly differs when the model is converted to onnx type.
Handle yolo.py and export.py as follows (modify when exporting onnx, not during training)

Before the detection header is processed, the three detection headers are combined
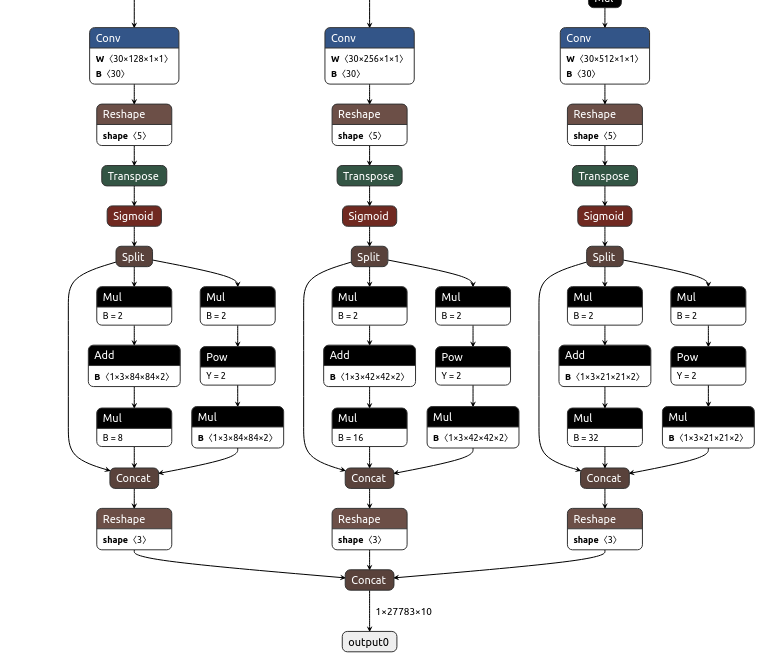
After the above operation, the onnx model is exported, part of the processing is removed, and the model has three outputs, corresponding to the post-processing code given by the official
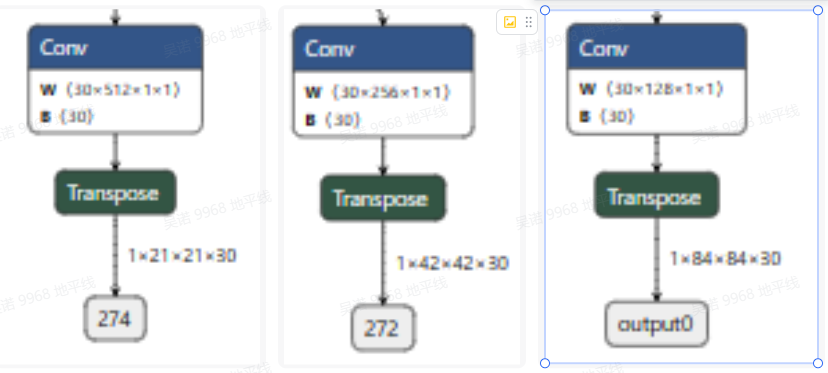
Note that the official post-processing code corresponds to 672x672 pictures, 80 categories. This is the 672x672.5 classification, so you also need to change the number of categories in post-processing.
As well as:
1. It is recommended to change the activation function silu to relu, otherwise some calculations will run on the CPU due to operator restrictions. The model/common.py is modified as follows (modified before training) :
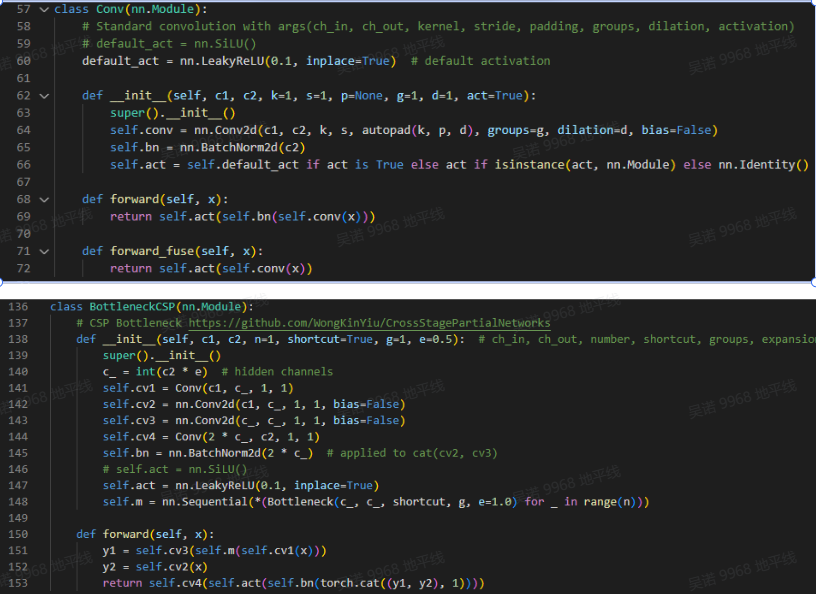
Without changing the activation function, the inference speed is only about 10 frames. Because of the changes in the beginning of the new version of the model, all operators run on the BPU after replacing the activation function, so it is no problem to run over 30 frames, but it is necessary to determine whether replacing the activation function will affect the inference accuracy of the model according to your actual situation
2. If you still want to use an output header, you can modify the corresponding post-processing code, but the BPU does not support reshape operations, so certain adjustments need to be made to export the onnx model. There should be some improvement in performance, but it is very limited. 30 frames is basically enough for most needs.